People say if you separate services and let them scale independently, you can will get better performance by allocating what’s needed and no computation resources will be wasted.
But how exactly? And how much gain will there be compared to a monolithic solution? This article will do a quantified research.
TL;DR
See conclusion
Method
Let’s say there are 2 services, A and B. They have different RT (Response Time) . B’s RT is twice as A’s, if they are running on the same CU (compute unit)
Let’s compare the overall QPS (Queries per second) per CU if we bundle them together (monolith) , against if we distribute them (micro services) .
A and B both require at least 1 CU to run (minimum compute resource).
And to make QPS comparison fair, here we introduce a concept of “work weight” . Finishing 100 heavy queries per second is not the same as finishing 100 light queries per second. Here we define that a work unit’s weight is twice as the other if its RT is twice as the other.

A and B can be in parallel (both A and B serve requests directly and they don’t call each other), or they be serial (A calls B or B calls A to serve a request)
A and B run in parallel
In the case of running in parallel, request distribution for different services is a factor that will decide how many CU you put for A and for B. Services that have more weighted requests should need more CU.
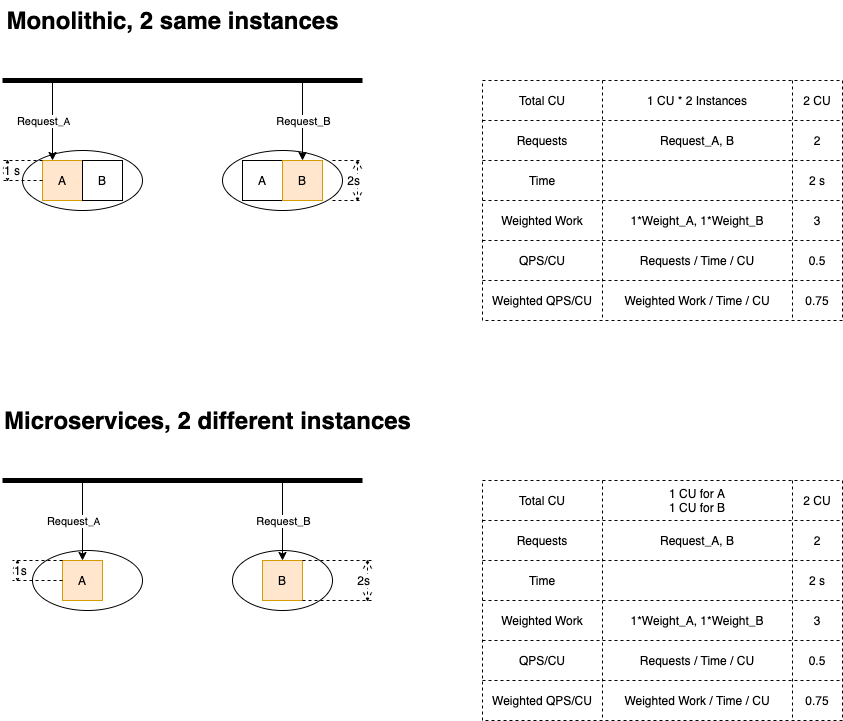
Parallel, request distribution is A:B = 1:1
Parallel, request distribution is A:B = 1:2
Parallel, request distribution is A:B = 2:1

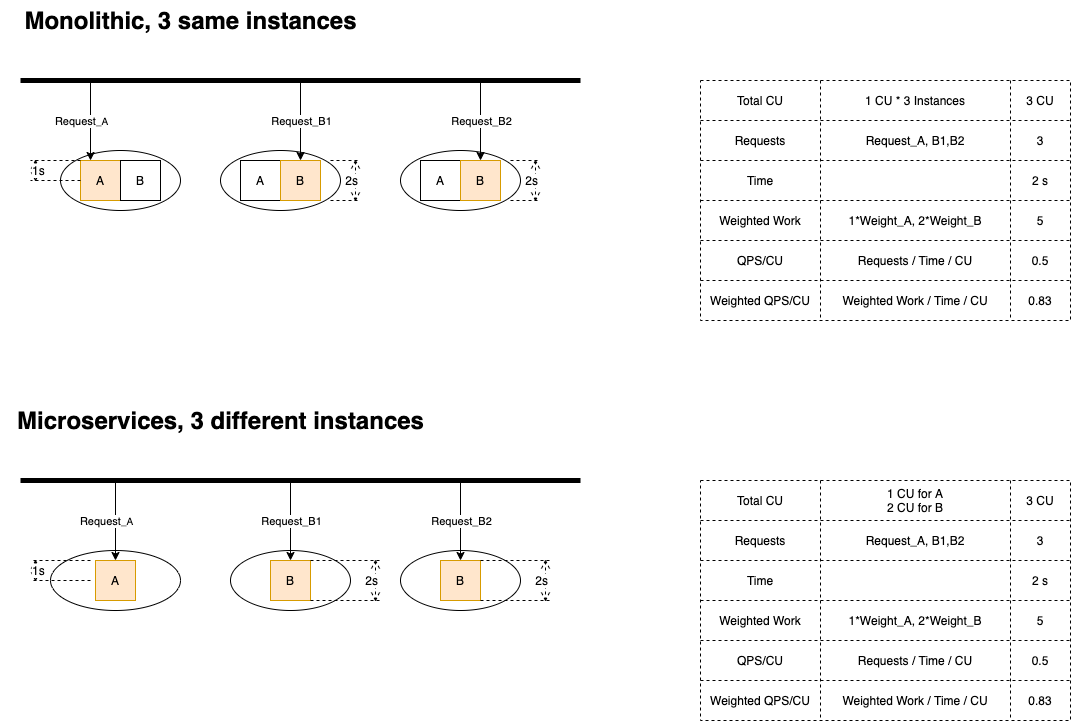
Parallel, request distribution is A:B = 4:1

A summary of parallel mode
| Request distribution | Bundled or Distributed | QPS/CU | Weighted QPS/CU |
| 1:1 | Bundled | 0.5 | 0.75 |
| Distributed | 0.5 | 0.75 | |
| 1:2 | Bundled | 0.5 | 0.83 |
| Distributed | 0.5 | 0.83 | |
| 2:1 | Bundled | 0.75 | 1 |
| Distributed | 0.75 | 1 | |
| 4:1 | Bundled | 0.83 | 1 |
| Distributed | 0.83 | 1 |
The performance of bundled mode and that of distributed are always the same! Surprising?
Think about it this way: What difference does it make between a request going through Service A in a bundled instance, and the same request going through a dedicated Service A instance? No difference. There only thing is that in a bundled instance, there is code of Service B there , but it is not activated. A sleeping code doesn’t mean anything in terms of performance.
A and B run in series
In this mode, request distribution doesn’t make sense. Only difference is who calls who.
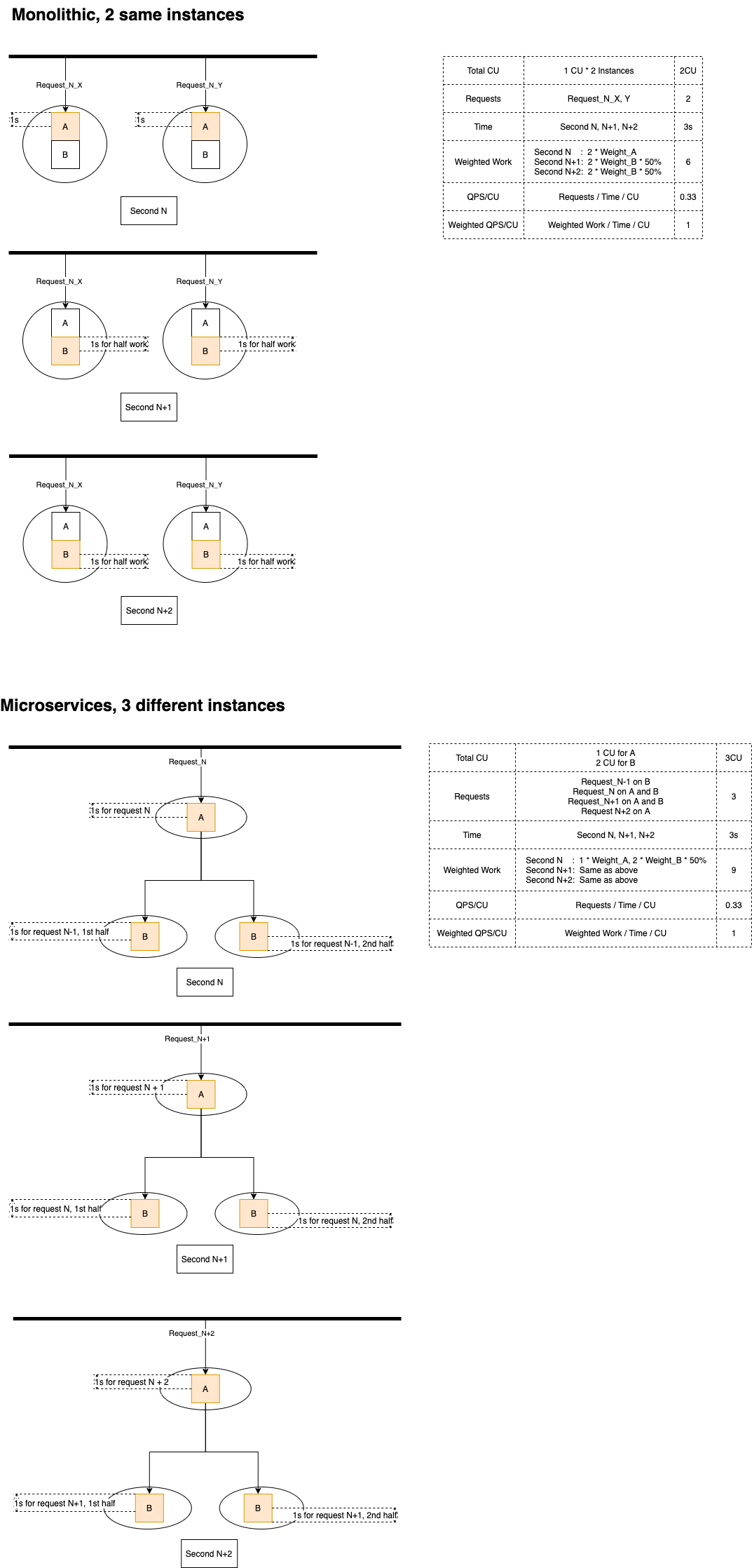
A calls B
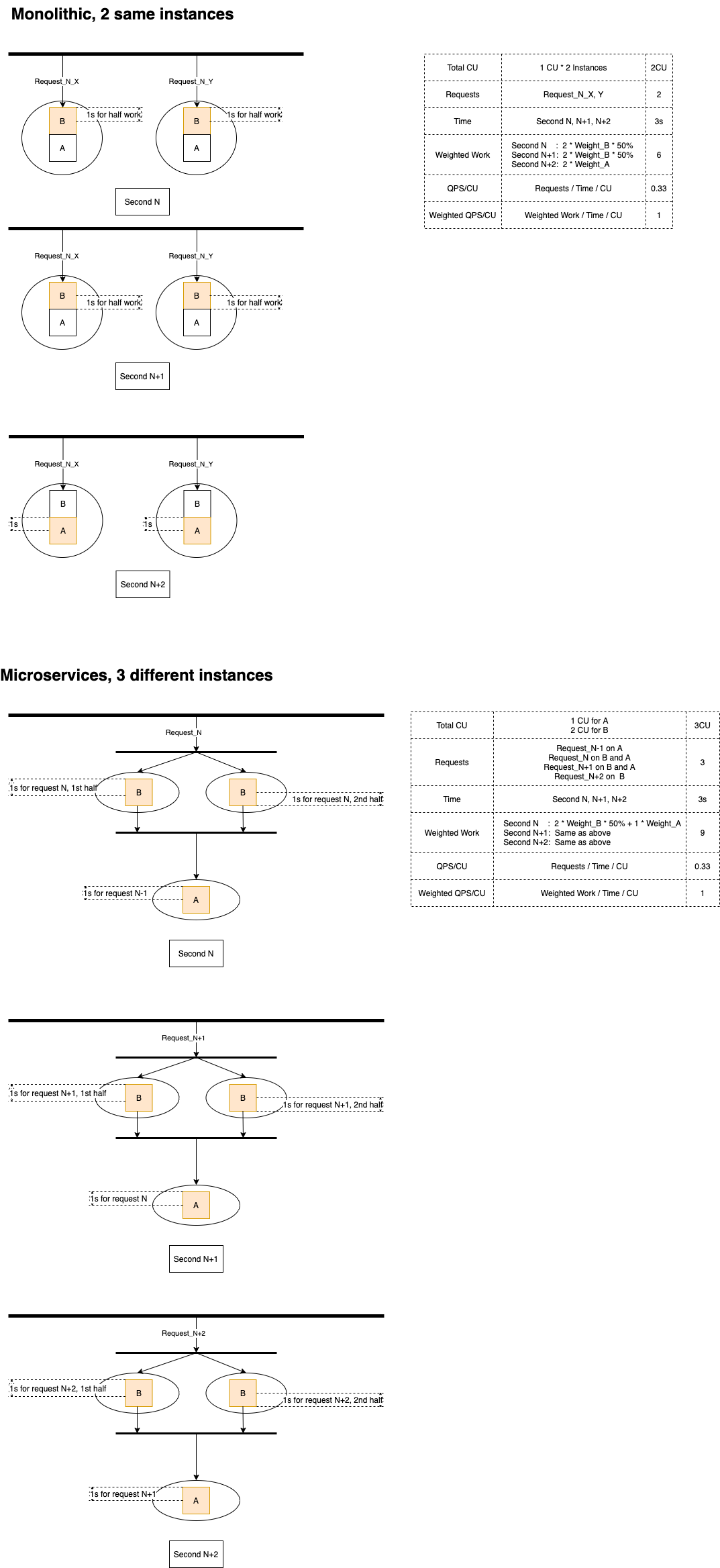
B calls A
A summary of serial mode
| Who calls who | Bundled or Distributed | QPS/CU | Weighted QPS/CU |
| Light service calls heavy service | Bundled | 0.33 | 1 |
| Distributed | 0.33 | 1 | |
| Heavy service calls light service | Bundled | 0.33 | 1 |
| Distributed | 0.33 | 1 |
Again, the performance of bundled mode and the performance of distributed are always the same!
Why isn’t the distributed mode better? When an instance of service B is working, the instance of service A is also working. The work at the same time. Why isn’t it better in terms of performance?
The truth is, while A and B are both working, improving simultaneousness, they also consume more computation resources. This in reality offsets the performance gain brought by simultaneous working.
Conclusion
If services need the same minimum computing resource to run, then no matter if services work in parallel, or they work in series, the performance of bundled deployment (monolith) and the performance of distributed deployment (micro-services) are the same . Microservices is NOT doing better than monolith.
But what if services need different minimum computing resources to run? That’s what we’re going to find out in the next article.